Ahora lo que queremos es justificar la estructura de grupo de una curva elíptica y si nos da tiempo de una hiperelíptica de género 2, pero para eso debemos introducir el concepto de divisores sobre la variedad y "género" el cual estará estrechamente relacionado con la dimensión de un espacio vectorial de funciones generado con un divisor.
Valuaciones
Vamos a suponer que $latex \mathbb{K}$ es un campo arbitrario el cual será un campo de constantes de algo más grande... el campo de funciones.
Definición 1: Una extensión $latex \mathbb{F}$ de $latex \mathbb{K}$ es un campo de funciones algebraico en una variable sobre $latex \mathbb{K}$ si existe un $latex z\in \mathbb{F}$ trascendente sobre $latex \mathbb{K}$ de tal manera que $latex [\mathbb{F}:\mathbb{K}(z)]$ es finita.
Los objetos centrales en esto serán los lugares, denotados por $latex P$ que de manera resumida serán los ideales máximos de todos los anillos de valuación que existan en $latex \mathbb{F}$ recuerden que los anillos de valuación son locales por lo que sólo tienen un ideal máximo, este anillo como en la parte uno lo denotaremos por $latex O_p$ y su ideal máximo como $latex M_p$
Recuerden como eran las funciones regulares de una variedad $latex V$ en un punto de la parte 1 de este blog la cual habíamos denotado como $latex O_p(V)=\lbrace f/g \in \mathbb{K}(V) : g(p)\neq 0 \rbrace$
Nota 1:
Aquí tenemos que $latex \mathbb{F}$ tiene un elemento trascendente y es campo por lo que podemos imaginarlo como que es on cociente de funciones polinomiales en una variable, pero podría ser que $latex \mathbb{K}$ sea ya un campo de funciones y $latex z\in \mathbb{F}$ otro elemento trascendente, haciendo que el campo de constantes no sea tan trivial.
Definición 2: Una valuación discreta normalizada de un campo de funciones algebraico $latex \mathbb{F}$ sobre $latex \mathbb{K}$ es un mapeo suprayectivo:
$latex \nu:\mathbb{F}\rightarrow \mathbb{Z}\cup \lbrace \infty \rbrace$
que satisface:
- $latex \nu(f)=\infty \Leftrightarrow f=0$
- $latex \nu(fg)=\nu(f)+\nu(g)$ $latex \forall f,g\in\mathbb{F}$
- $latex \nu(f+g) \geq min(\nu(f),\nu(g))\Rightarrow\nu(f+g)=min(\nu(f),\nu(g))$ $latex \forall f,g\in \mathbb{F}$
- $latex \nu(a)=0$ $latex \forall a\in \mathbb{K}^{*}$
Estos mapeos están en correspondencia biunívoca con los lugares de $latex \mathbb{F}$ por lo que si $latex P$ es un lugar de $latex \mathbb{F}$ definiremos como $latex \nu_P$ a su valuación correspondiente y denotaremos por $latex \mathbb{P}_\mathbb{F}$ a el conjunto de todos los lugares de $latex \mathbb{F}$
Nota 2: Recordemos que cuando vimos en la parte 1 el anillo de funciones regulares en una variedad, tenemos que los puntos están en correspondencia con los ideales máximos, aquí estámos usando por eso los lugares que son los ideales máximos pero lo estamos generalizando un poquito más con estas estructuras, que en vez de considerar los puntos , consideramos los ideales máximos de la localización.
Ahora vamos a definir los anillos locales en términos de valuaciones y lo ilustraremos con un ejemplo sencillo, estos anillos serán llamados anillos de valuación discreta de $latex \mathbb{F}$ correspondientes al lugar $latex P\in \mathbb{P}_\mathbb{F}$
$latex O_P=\lbrace f\in \mathbb{F} : \nu_P(f) \geq 0\rbrace$
Es fácil demostrar que es un anillo local, basta considerar quiénes son los elementos invertibles para saber que su ideal máximo (que obviamente no tiene elementos invertibles) es:
$latex M_P = \lbrace f\in O_P : \nu_P(f)>0 \rbrace$
Como $latex M_P$ es máximo definiremos el campo residual
$latex \hat{\mathbb{F}}_P:=O_P/M_P$
y definiremos el grado de $latex P$ como el grado de la extensión $latex grad(P):= [\hat{\mathbb{F}}_P:\mathbb{K}]$ , cuando $latex grad(P)=1$ diremos que $latex P$ es racional
Bueno, yo recuerdo que cuando leí esto por primera vez se me hacía muy mágico el mapeo $latex \nu_P$
por lo que creo que es conveniente ilustrarlo con un ejemplo.
Ejemplo:
Sea $latex \mathbb{F}=\mathbb{K}(x)$ con $latex x$ trascendente sobre $latex \mathbb{K}$ es decir estamos considerando todos los cocientes de polinomios en una variable sobre el campo $latex \mathbb{K}$ aquí tenemos que los mónicos irreducibles $latex P(x)\in \mathbb{K}[x]$ nos inducen una valuación discreta única $latex \nu_P$
$latex \nu_P(f(x)) = r$ si $latex f(x)\in \mathbb{K}[x]-\lbrace 0 \rbrace$ y $latex P(x)^r \mid f(x)$
$latex O_P = \Bigg \lbrace \frac{f(x)}{g(x)} \in \mathbb{F} : P(x)\nmid g(x) \Bigg \rbrace$
Es clara esta definición ya que si $latex P(x)\mid g(x)$ es decir no se cancela en $latex f(x)$ la valuación sería negativa y tenemos que el anillo está formado por los elementos que tienen valuación mayor o igual que cero
Ahora, su ideal máximo ¿quién es?, tenemos que no tiene que tener elementos invertibles en $latex O_P$ y que su valuación sea estrictamente mayor que 0, eso significa que $latex P(x) \mid f(x)$ y como es subconjunto de $latex O_P$ también tiene que suceder que $latex P(x) \nmid g(x)$ por lo que en símbolos.
$latex M_P=\Bigg \lbrace \frac{f(x)}{g(x)} \in \mathbb{F} : P(x)\mid f(x), P(x)\nmid g(x) \Bigg \rbrace$
Entonces a qué huelen los elementos invertibles de $latex O_P$ ? pues son todos los que NO tienen a $latex P(x)$ involucrado en el cociente $latex \frac{f(x)}{g(x)}$ es decir , los que tienen su valoración exactamente 0.
Entonces en este ejemplo cuando $latex P$ es linealtenemos que
$latex \mathbb{F}/(P(x)) \cong \mathbb{K}$
Es decir, los lugares $latex P$ RACIONALES son aquellos generados con polinomios mónicos lineales.
Aquí en este ejemplo y en todos los interesantes, es decir cuando consideremos curvas elípticas o hiperelípticas hay otro anillo de valuación que no está asociado a un polinomio pero pueden demostrar que es anillo y que tiene un sólo ideal máximo
$latex O_\infty = \Bigg \lbrace \frac{f(x)}{g(x)} \in \mathbb{F}, g(x)\neq 0, grad(f(x)) \leq grad(g(x)) \Bigg \rbrace $
y su ideal máximo
$latex M_\infty =\Bigg \lbrace \frac{f(x)}{g(x)} \in \mathbb{F}, g(x)\neq 0, grad(f(x)) < grad(g(x)) \Bigg \rbrace $
Es fácil ver esto , y que los invertibles tienen el mismo grado tanto en el numerador como denonimador.
Esto le llamaremos el lugar infinito de $latex \mathbb{F}$ y como ejercicio podrían demostrar que $latex O_\infty/M_\infty \cong \mathbb{K}$ por lo que otra vez tenemos un lugar RACIONAL es decir, el lugar infinito es racional, si el lugar tiene relacionado un polinomio diremos que es finito.
Observación:
Si $latex \mathbb{K}=\mathbb{F}_q$ es finito entonces hay $latex q+1$ lugares racionales, el +1 es por el lugar infinito
Divisores
Los divisores son esencialmente sumas formales de lugares junto con un coeficiente, esto será intuitivamente una expresión que nos ayudará a juntar ciertas características de elementos del campo de funciones
Definición 3: Un divisor $latex D$ de un campo de funciones algebraico $latex \mathbb{F}$ es una suma formal:
$latex D=\sum_{P\in \mathbb{P}_\mathbb{F}}m_P P$
Donde un número finito de $latex m_P$ es distinto de cero, este conjunto de divisores los denotamos por $latex Div(F)$
El soporte de un divisor es:
$latex sop(D):= \lbrace P\in \mathbb{P}_\mathbb{F} : m_P \neq 0\rbrace$
El grado de un divisor es:
$latex \partial(D):=\sum_{P \in sop(D)} (m_P)grad(P)$
Se dice que un divisor $latex D$ es positivo/efectivo si todos sus $latex m_P$ son mayores o iguales que 0, y escribimos $latex \nu_P(D) \geq 0$ .
Si dos divisores $latex D_1,D_2 \in Div(\mathbb{F})$ los comparamos como $latex D_1 \leq D_2$ si $latex \nu_P(D_1) \leq \nu_P(D_2)$ para todo $latex P \in \mathbb{P}_\mathbb{F}$, es decir que todos los coeficientes de los sumandos de los divisores son menores o iguales.
Es claro que $latex Div(\mathbb{F})$ forma un grupo abeliano con suma definida componente a componente y es un grupo libre, y que un subgrupo de éste son los divisores de grado 0, que lo denotaremos por $latex Div^0(\mathbb{F})$
Definición 4: Decimos que si $latex \nu_P(f)$ > $latex 0$ entonces $latex P$ es un cero de multiplicidad $latex \nu_P(f)$ y si $latex \nu_P(f)$ < $latex 0$ decimos que es un polo
Es claro que las constantes no tienen ceros ni polos, pero los demas elementos $latex f\in \mathbb{F}$
tienen al menos un cero y un polo.
Definición 5: Sea $latex f\in \mathbb{F}^{*}$ y $latex Z(f),N(f)$ los ceros y los polos de $latex f$ respectivamente, entonces definimos:
divisor de ceros de $latex f$:
$latex (f)_0 = \sum_{P\in Z(f)}\nu_P(f)P$
divisor de polos de $latex f$:
$latex (f)_\infty = \sum_{P\in N(f)}-\nu_P(f)P$
divisor principal de $latex f$:
$latex div(f):=(f)_0 - (f)_\infty$
Aquí sucede algo que habría que demostrar y no es tan directo pero si es lógico.
Que todos los divisores principales tienen grado 0, es decir, $latex \partial(div(f))=0$ para todo $latex f\in \mathbb{F}^{*}$, o sea existe el mismo número de ceros y de polos en los elementos de $latex \mathbb{F}$, esto lo pueden ver en el libro de Algebraic function fields and codes de Henning Stichtenoth.
Definición 5: El espacio de Riemann-Roch para un divisor $latex D$ de $latex \mathbb{F}$ está definido como:
$latex \mathfrak{L}(D):= \lbrace f\in \mathbb{F}^{*} : div(f)+D \geq 0 \rbrace \cup \lbrace 0 \rbrace $
Este espacio es un espacio vectorial sobre $latex \mathbb{K}$ y su dimensión será denotada por $latex l(D)$
Hay cosas que podrían demostrarse por ejercicio que son muy directas como que $latex l(0)=1$ o que $latex l(D)=0$ si $latex \partial(D)$ < $latex 0$
Teorema (Riemann-Roch): Sea $latex \mathbb{F}$ un campo de funciones algebraico de género $latex g$ , entonces para cada divisor $latex D$ de $latex \mathbb{F}$ tenemos que:
$latex l(D)\geq \partial(D)+1-g$
donde la igualdad se da si $latex \partial(D)\geq 2g-1$
Este teorema es muy potente y sirve de clasificación para campos de funciones con respecto al género
Definición 6:
El género $latex g$ de un campo de funciones $latex \mathbb{F}$ se define como:
$latex g:= g(\mathbb{F}):=max_D(\partial(D)-l(D)+1)$
O sea el máximo de todos los divisores de $latex \mathbb{F}$, tenemos que el género del ejemplo $latex \mathbb{K}(x)$ es 0 y decimos que el campo de funciones $latex \mathbb{F}$ es elíptico si su género es 1
Definición 7:
Sea $latex P\in \mathbb{P}_\mathbb{F}$ , $latex \forall$ $latex n \geq 1$ es número de polo para $latex P$ si existe un elemento $latex f\in \mathbb{F}^{*}$ tal que $latex (f)_\infty = nP$, si no existe esto decimos que $latex n$ es número de salto para $latex P$
Corolario (Saltos de Weierstrass):
Sea $latex \mathbb{F}$ de género $latex g\geq 1$ y sea $latex P$ un lugar racional de $latex \mathbb{F}$, entonces existen exactamente $latex g$ número de salto $latex i_j$ que satisfacen:
$latex 1=i_1$ < ... < $latex i_g \leq 2g-1$
Esto se sigue inmediatamente de que:
- $latex \forall i\geq 1$ tenemos que $latex \mathfrak{L}((i-1)P)\subseteq \mathfrak{L}(iP)$ y $latex \mathfrak{L}((i-1)P)=\mathfrak{L}(iP) \Leftrightarrow i$ es número de salto
- $latex l(iP)\leq l((i-1)P)+1$
- $latex l(0P)=1$ y $latex l((2g-1)P)=g$
Criptografía
Ya habíamos mencionado que todos los divisores de funciones tienen grado 0 es decir tienen el mismo número de ceros y de polos. por lo que estos serían un subgrupo de $latex Div^{0}(\mathbb{F})$
entonces el subgrupo de divisores principales lo denotamos como:
$latex Prin(\mathbb{F}):= \lbrace div(f) : f\in \mathbb{F}^{*}\rbrace \subset Div^{0}(\mathbb{F})$
Como estos grupos son libres, abelianos, podemos hablar de su cociente, por lo que el grupo que necesitamos para criptografía y el que se usa actualmente es el grupo de Picard de orden 0 el cual es isomorfo a:
$latex Pic^{0}(\mathbb{F}):= Div^0(\mathbb{F})/Prin(\mathbb{F})$
Si el género del campo de funciones $latex \mathbb{F}$ es 1 este grupo es isomorfo al grupo usual que conocemos de las curvas elípticas y si es 2 se dice que es hiperelíptico.
De hecho, para culminar este post, vemos que no necesitamos el teorema de bézout para demostrar que una recta intersecta en 3 puntos a una curva proyectiva ya que:
Ya conocemos estas propiedades de los divisores de funciones por el hecho de que sabemos que tienen el mismo número de ceros que de polos por lo que:
Tenemos que si $latex f,g \in \mathbb{F}=\overline{\mathbb{K}}(C)$ es el campo de funciones de una curva elíptica (i.e. cúbica)
$latex div(f/g)=div(f)-div(g)$
$latex div(fg)=div(f)+div(g)$
$latex div(f^n)=n\cdot div(f)$
Nota sobre funciones en la curva: Es importante considerar que para entender un objeto algebraico, hay que entender las funciones en éste, y si son proyectivos, cosas interesantes pasan, por ejemplo si tenemos la curva elíptica $latex C(x,y)=y^2 - x^3 + x$
Considera la función racional $latex q(x,y)= x/y \in \mathbb{F}=\hat{\mathbb{K}}(C)$ , podemos ver que $latex q(1,0)=\infty$ pero $latex q(0,0)=??$ , pero si usamos que esta función pertenece a la curva elíptica $latex C$ por lo que bajo la relación algebraica $latex y^2 = x^3 - x$ tenemos que $latex x/y = y/(x^2+1)$ por lo que en la curva, es decir en su campo de funciones $latex q(0,0)=0$.
Criptografía con campos de funciones elípticos vía teorema de Riemann-Roch.
Si consideramos la curva proyectiva elíptica $latex C$ homogeneizada con la variable $latex z$
aquí los ideales máximos son los puntos de la curva, y los anillos locales son las funciones racionales definidas en cada punto.
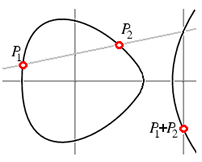
Si tomamos la linea $latex l_PQ$ que pasa por los puntos $latex P,Q \in \mathbb{P}_\mathbb{F}$
tal que la linea tiene pendiente finita, como demostramos en la parte 2, esta linea choca con otro punto al infinito que es el que corresponde al lugar infinito , veamos que multiplicidad tiene,
y sin usar bezout y con todos los teoremas anteriores, tenemos que si la multiplicidad es n entonces debe de haber n lugares en el divisor correspondiente a la linea porque $latex \partial(div(l_{PQ}))=0$
Tenemos que una curva elíptica es de la forma $latex y^2 = x^3 + \alpha x + \beta$
y $latex l_{PQ}$ es $latex y=mx+b$ por lo que si elevamos al cuadrado la linea e intersectamos con la curva
$latex (mx+b)^2 = x^3 + \alpha x + \beta$ es una cúbica en $latex x$ y en la homogenización tiene un cero de orden 3 en el punto al infinito $latex [1:0:1]$ el cual es el polo.
Eso quiere decir que si tenemos un polo de orden 3 , deben de haber 3 puntos donde choca la linea.
En símbolos:
La recta con pendiente distinta de 0 en la curva que pasa por P y Q:
$latex div(l_{PQ}/z) = (P)+(Q)+(R)-3\infty $
La recta que proyecta con el lugar infinito y R
$latex div(l_{R,\infty}/z)= R+(P+Q) -2\infty$
Por lo que:
$latex div(l_{PQ}/l_{R,\infty})=$ $latex div(l_{PQ}/z)-div(l_{R,\infty}/z)=(P)+(Q)-(P+Q)-\infty$
Por lo que de aquí sale la razón por la que está definida
Aquí vemos como se ven los divisores

Y de hecho, el grupo de Picard en este caso es isomorfo a los puntos de la curva bajo el mapeo:
$latex \Psi:C\rightarrow Pic^0(C)$
$latex P \mapsto P-\infty + Prin(\mathbb{F})$
Esto es inyectivo porque en género 1 con Riemann-Roch , ningún divisor $latex (P)-\infty$ es principal a menos que $latex P=\infty$
Espero les haya gustado
Eduardo Ruíz Duarte (beck)
twitter: @toorandom